

티스토리 뷰
웹 서비스를 만들다 보면 요청을 받자마자 바로 처리하기 어려운 작업을 만나게 됩니다.
예를 들어 사용자가 회원가입을 했을 때 환영 이메일을 보내야 할 수 있습니다.
이미지를 업로드하면 썸네일을 생성해야 할 수도 있고, 외부 API와 데이터를 동기화해야 할 수도 있습니다.
이런 작업을 HTTP 요청 안에서 모두 처리하면 사용자는 응답을 오래 기다려야 합니다.
사용자 요청
→ 이메일 발송
→ 이미지 처리
→ 외부 API 호출
→ DB 저장
→ 응답 반환작업이 조금만 느려져도 페이지가 늦게 뜨고, API 응답 시간이 길어지고, 타임아웃이 발생할 수 있습니다.
이때 사용하는 대표적인 방식이 작업 큐(Task Queue)입니다.
Django 프로젝트에서는 작업 큐를 구현할 때 Celery를 많이 사용합니다.
이번 글에서는 Celery와 작업 큐가 무엇인지, 왜 필요한지, Django에서 어떤 흐름으로 사용하는지 정리해보겠습니다.
오래 걸리는 작업은 왜 문제가 될까?
웹 요청은 보통 빠르게 처리되는 것이 좋습니다.
사용자가 버튼을 눌렀을 때 서버는 요청을 받고, 필요한 작업을 처리한 뒤, 가능한 한 빠르게 응답을 반환해야 합니다.
예를 들어 게시글 작성 API를 생각해보겠습니다.
POST /posts
→ 게시글 저장
→ 응답 반환이 정도는 비교적 단순합니다.
하지만 게시글 작성 후에 다음 작업까지 함께 처리해야 한다면 어떨까요?
POST /posts
→ 게시글 저장
→ 이미지 리사이징
→ 검색 인덱스 업데이트
→ 구독자 이메일 발송
→ 외부 분석 API 호출
→ 응답 반환이 모든 작업을 요청 안에서 처리하면 사용자는 모든 작업이 끝날 때까지 기다려야 합니다.
문제는 다음과 같습니다.
- 응답 시간이 길어집니다.
- 외부 API가 느리면 전체 요청도 느려집니다.
- 이메일 서버 장애가 사용자 요청 실패로 이어질 수 있습니다.
- 이미지 처리처럼 CPU를 많이 쓰는 작업이 웹 서버에 부담을 줄 수 있습니다.
- 요청 타임아웃이 발생할 수 있습니다.
- 사용자는 실제로 기다릴 필요 없는 작업까지 기다리게 됩니다.
그래서 실무에서는 “사용자에게 즉시 응답해야 하는 작업”과 “나중에 처리해도 되는 작업”을 분리하는 경우가 많습니다.
작업 큐란?
작업 큐는 오래 걸리거나 나중에 처리해도 되는 작업을 큐에 넣고, 별도의 작업 처리자가 하나씩 꺼내 처리하는 구조입니다.
단순하게 표현하면 다음과 같습니다.
웹 서버
→ 작업을 큐에 넣음
워커
→ 큐에서 작업을 꺼냄
→ 실제 작업 수행예를 들어 회원가입 후 환영 이메일을 보내는 흐름을 생각해보겠습니다.
동기 처리 방식은 다음과 같습니다.
회원가입 요청
→ 사용자 생성
→ 이메일 발송 완료까지 대기
→ 응답 반환작업 큐 방식은 다음과 같습니다.
회원가입 요청
→ 사용자 생성
→ 이메일 발송 작업을 큐에 등록
→ 바로 응답 반환
이후 별도 worker
→ 큐에서 이메일 작업 꺼냄
→ 이메일 발송사용자는 이메일 발송이 끝날 때까지 기다릴 필요가 없습니다.
서버는 필요한 작업을 큐에 맡기고 빠르게 응답할 수 있습니다.
Celery란?
Celery는 Python에서 많이 사용하는 분산 작업 큐 라이브러리입니다.
Django, Flask, FastAPI 같은 Python 웹 프레임워크와 함께 사용할 수 있습니다.
Celery를 사용하면 다음과 같은 작업을 백그라운드에서 처리할 수 있습니다.
- 이메일 발송
- 이미지 리사이징
- 파일 변환
- 대용량 데이터 처리
- 외부 API 호출
- 보고서 생성
- 알림 발송
- 주기적인 배치 작업
- 검색 인덱스 업데이트
- 웹훅 처리
Celery는 직접 작업을 저장하는 큐 자체라기보다, 작업을 정의하고 실행하고 관리하는 프레임워크에 가깝습니다.
실제로 작업 메시지를 주고받기 위해서는 보통 메시지 브로커가 필요합니다.
대표적인 브로커는 다음과 같습니다.
- Redis
- RabbitMQ
Django 프로젝트에서 Celery를 사용할 때는 Redis를 브로커로 많이 사용합니다.
RabbitMQ는 메시지 큐 기능이 강력하고 Celery와도 오래 사용되어 온 선택지입니다.
Celery의 기본 구성요소
Celery를 이해하려면 몇 가지 구성요소를 알아야 합니다.
1. Producer
Producer는 작업을 큐에 넣는 쪽입니다.
Django 웹 서버가 보통 Producer 역할을 합니다.
예를 들어 사용자가 회원가입하면 Django view에서 이메일 발송 작업을 큐에 등록합니다.
Django web server
→ send_welcome_email 작업 등록2. Broker
Broker는 작업 메시지를 임시로 보관하고 전달하는 중간 저장소입니다.
Celery에서는 Redis나 RabbitMQ를 브로커로 사용할 수 있습니다.
Django
→ Broker에 작업 메시지 전달
→ Worker가 Broker에서 작업 수신3. Worker
Worker는 큐에 쌓인 작업을 실제로 처리하는 프로세스입니다.
웹 서버와는 별도로 실행됩니다.
celery worker
→ 작업 꺼내기
→ 이메일 발송
→ 이미지 처리
→ 외부 API 호출4. Result Backend
Result Backend는 작업 결과를 저장하는 저장소입니다.
모든 작업에서 반드시 필요한 것은 아닙니다.
예를 들어 이메일 발송처럼 성공 여부만 로그로 보면 되는 작업은 결과 저장이 꼭 필요하지 않을 수 있습니다.
하지만 작업 상태를 조회해야 한다면 Result Backend를 사용할 수 있습니다.
작업 ID
→ PENDING
→ STARTED
→ SUCCESS
→ FAILURE5. Beat
Celery Beat는 주기적인 작업을 실행하기 위한 스케줄러입니다.
예를 들어 매일 새벽 3시에 통계 리포트를 생성하거나, 10분마다 외부 API와 데이터를 동기화할 때 사용할 수 있습니다.
Celery 작업 처리 흐름
Celery를 사용하는 기본 흐름은 다음과 같습니다.
- 사용자가 웹 요청을 보냅니다.
- Django view가 즉시 처리해야 하는 작업을 처리합니다.
- 오래 걸리는 작업은 Celery task로 등록합니다.
- 작업 메시지가 Broker에 들어갑니다.
- Celery Worker가 Broker에서 작업을 가져옵니다.
- Worker가 실제 작업을 처리합니다.
- 필요한 경우 결과를 Result Backend에 저장합니다.
단순화하면 다음과 같습니다.
Client
→ Django Web Server
→ Broker
→ Celery Worker
→ External Service / Database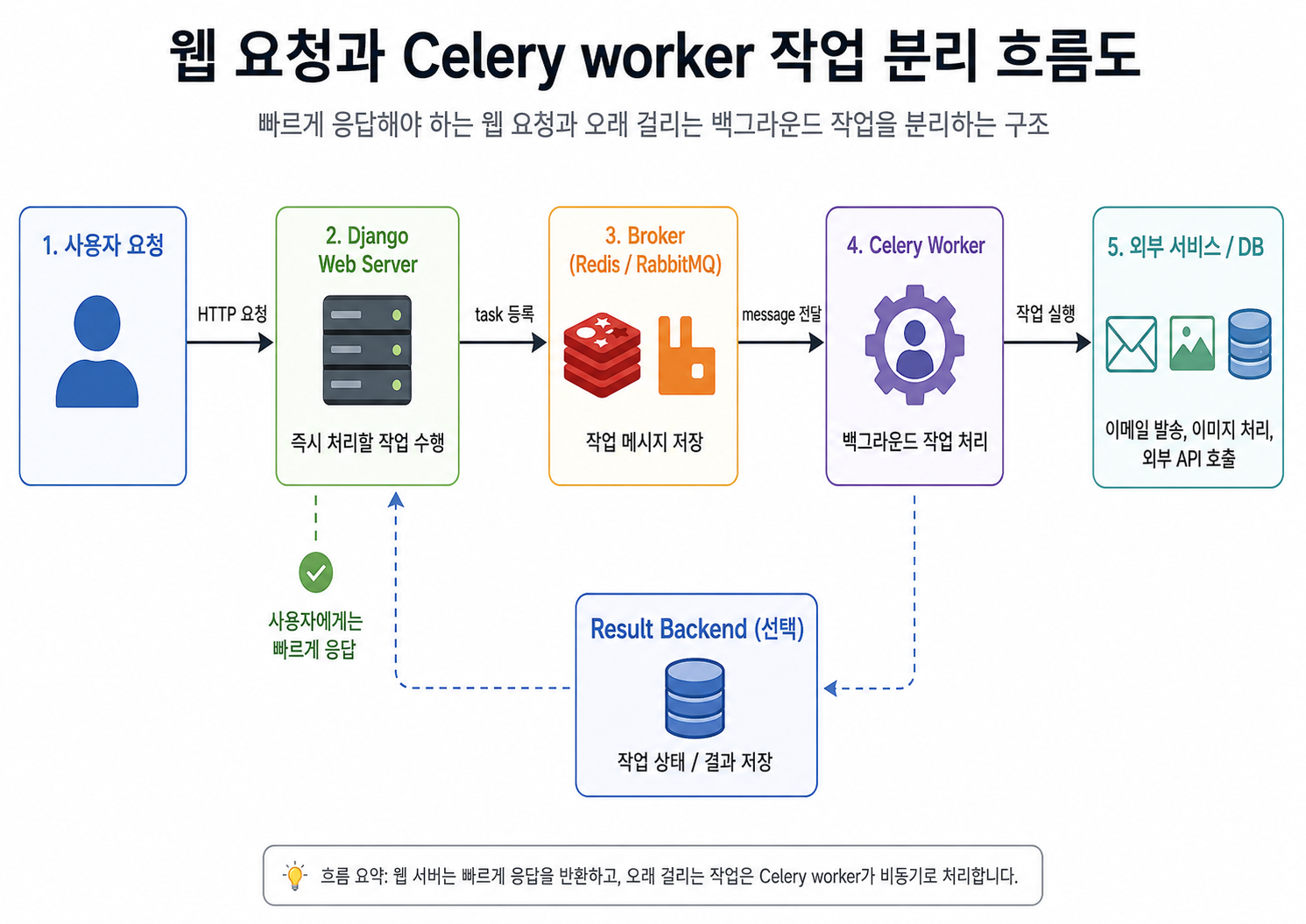
동기 처리와 작업 큐 처리 비교
예를 들어 사용자가 이미지 파일을 업로드한다고 해보겠습니다.
이미지를 업로드하면 서버는 다음 작업을 해야 합니다.
- 원본 이미지 저장
- 썸네일 생성
- 이미지 메타데이터 추출
- CDN 업로드
- 완료 알림 발송
동기 방식에서는 사용자가 이 모든 작업이 끝날 때까지 기다려야 합니다.
요청 시작
→ 이미지 저장
→ 썸네일 생성
→ CDN 업로드
→ 알림 발송
→ 응답 반환작업 큐 방식에서는 사용자에게 필요한 최소 작업만 처리한 뒤, 나머지는 백그라운드로 보낼 수 있습니다.
요청 시작
→ 원본 이미지 저장
→ 백그라운드 작업 등록
→ 응답 반환
이후 worker
→ 썸네일 생성
→ CDN 업로드
→ 알림 발송이 방식의 장점은 명확합니다.
- 사용자가 빠르게 응답을 받을 수 있습니다.
- 외부 서비스 장애가 사용자 요청 전체를 막지 않게 할 수 있습니다.
- 오래 걸리는 작업을 별도 worker로 분리할 수 있습니다.
- 작업 실패 시 재시도 전략을 적용할 수 있습니다.
- worker 수를 늘려 작업 처리량을 조절할 수 있습니다.

async/await와 Celery는 무엇이 다를까?
앞에서 비동기 프로그래밍을 다룬 적이 있습니다.
그렇다면 이런 질문이 생길 수 있습니다.
async/await를 쓰면 되지, 왜 Celery가 필요할까?
둘은 해결하려는 문제가 다릅니다.
async/await
async/await는 주로 하나의 애플리케이션 안에서 I/O 대기 시간을 효율적으로 활용하기 위한 방식입니다.
예를 들어 여러 외부 API를 동시에 호출하고 응답을 기다리는 상황에 유용할 수 있습니다.
하나의 요청 처리 중
→ 여러 I/O 작업을 효율적으로 대기Celery
Celery는 작업 자체를 웹 요청 밖으로 분리하고, 별도 worker 프로세스에서 처리하기 위한 방식입니다.
웹 요청
→ 작업 큐에 등록
→ 웹 요청은 빠르게 응답
→ worker가 나중에 처리즉, async/await는 요청 안에서 대기 시간을 효율적으로 쓰는 방식에 가깝고, Celery는 작업을 요청 밖으로 빼는 방식에 가깝습니다.
정리하면 다음과 같습니다.
async/await
→ 요청 처리 중 I/O 대기를 효율적으로 다루기
Celery
→ 오래 걸리는 작업을 백그라운드 worker로 분리하기둘은 경쟁 관계라기보다 서로 다른 문제를 해결하는 도구입니다.
Django에 Celery 연결하기
Django 프로젝트에 Celery를 연결하는 기본 구조를 살펴보겠습니다.
예를 들어 프로젝트 구조가 다음과 같다고 해보겠습니다.
myproject/
myproject/
__init__.py
settings.py
celery.py
posts/
tasks.py
views.py먼저 myproject/celery.py 파일을 만듭니다.
import os
from celery import Celery
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "myproject.settings")
app = Celery("myproject")
app.config_from_object("django.conf:settings", namespace="CELERY")
app.autodiscover_tasks()그 다음 myproject/__init__.py에서 Celery app을 로드합니다.
from .celery import app as celery_app
__all__ = ("celery_app",)Django 설정에는 broker URL을 추가합니다.
CELERY_BROKER_URL = "redis://localhost:6379/0"
CELERY_RESULT_BACKEND = "redis://localhost:6379/1"운영 환경에서는 Redis 주소, 비밀번호, TLS 설정 등을 환경변수로 관리하는 것이 좋습니다.
import os
CELERY_BROKER_URL = os.environ["CELERY_BROKER_URL"]Celery task 만들기
이제 Django app 안에 tasks.py를 만들고 task를 정의할 수 있습니다.
예를 들어 이메일 발송 작업을 만들어보겠습니다.
from celery import shared_task
from django.core.mail import send_mail
@shared_task
def send_welcome_email(user_email):
send_mail(
subject="가입을 환영합니다",
message="서비스 가입을 환영합니다.",
from_email="no-reply@example.com",
recipient_list=[user_email],
)@shared_task를 사용하면 Django app 안에서 Celery task를 정의할 수 있습니다.
이 task는 일반 함수처럼 보이지만, Celery worker가 실행할 수 있는 작업으로 등록됩니다.
task 호출하기
Celery task는 일반 함수처럼 바로 호출하면 안 됩니다.
send_welcome_email(user.email)이렇게 호출하면 백그라운드 작업이 아니라 현재 프로세스에서 바로 실행됩니다.
작업 큐에 등록하려면 delay() 또는 apply_async()를 사용합니다.
send_welcome_email.delay(user.email)예를 들어 회원가입 view에서 사용할 수 있습니다.
from rest_framework import status
from rest_framework.response import Response
from rest_framework.views import APIView
from .serializers import SignupSerializer
from .tasks import send_welcome_email
class SignupView(APIView):
def post(self, request):
serializer = SignupSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
user = serializer.save()
send_welcome_email.delay(user.email)
return Response(
{"message": "회원가입이 완료되었습니다."},
status=status.HTTP_201_CREATED,
)이제 이메일 발송은 worker가 처리하고, API는 빠르게 응답할 수 있습니다.
delay와 apply_async 차이
delay()는 task를 간단히 큐에 넣는 방법입니다.
send_welcome_email.delay(user.email)apply_async()는 더 세밀한 설정이 필요할 때 사용합니다.
예를 들어 10분 뒤에 실행하고 싶다면 countdown을 사용할 수 있습니다.
send_welcome_email.apply_async(args=[user.email], countdown=600)특정 큐로 보내고 싶다면 queue를 지정할 수 있습니다.
send_welcome_email.apply_async(
args=[user.email],
queue="email",
)작업 만료 시간을 둘 수도 있습니다.
send_welcome_email.apply_async(
args=[user.email],
expires=300,
)처음에는 delay()로 충분한 경우가 많습니다.
작업 지연 실행, 특정 큐, 우선순위, 만료 시간 같은 설정이 필요할 때 apply_async()를 사용하면 됩니다.
Celery worker 실행하기
task를 큐에 넣어도 worker가 실행 중이 아니면 작업이 처리되지 않습니다.
개발 환경에서는 다음처럼 worker를 실행할 수 있습니다.
celery -A myproject worker -l info여기서 myproject는 Celery app이 있는 Django 프로젝트 이름입니다.
특정 큐만 처리하는 worker를 실행할 수도 있습니다.
celery -A myproject worker -l info -Q email예를 들어 이메일 작업과 이미지 작업을 분리할 수 있습니다.
email queue
→ email worker
image queue
→ image worker이렇게 하면 작업 종류별로 worker 수를 다르게 조절할 수 있습니다.
Redis는 어떤 역할을 할까?
Django와 Celery를 함께 사용할 때 Redis를 자주 봅니다.
Redis는 여러 역할로 사용될 수 있습니다.
- Celery broker
- Celery result backend
- Django cache
- session store
- rate limiting 저장소
- 분산 lock
Celery에서 Redis가 broker로 사용될 때는 작업 메시지를 전달하는 중간 저장소 역할을 합니다.
Django
→ Redis에 task 메시지 저장
Celery worker
→ Redis에서 task 메시지 가져옴Redis는 설치와 사용이 비교적 간단해서 개발 환경이나 중소규모 프로젝트에서 자주 선택됩니다.
하지만 운영 환경에서는 Redis 장애, 메모리 사용량, persistence 설정, 네트워크 보안, 모니터링을 함께 고려해야 합니다.
RabbitMQ는 언제 고려할까?
RabbitMQ는 메시지 브로커로 널리 사용되는 도구입니다.
Celery와도 자주 함께 사용됩니다.
RabbitMQ는 메시지 큐 기능이 강력하고, 라우팅, exchange, queue, acknowledgement 같은 메시징 기능을 세밀하게 다룰 수 있습니다.
Redis와 RabbitMQ 중 무엇이 무조건 더 낫다고 말하기는 어렵습니다.
대략적인 선택 기준은 다음과 같습니다.
Redis
→ 설정이 단순하고 빠르게 시작하기 좋음
→ 캐시 등 다른 용도와 함께 사용하기 쉬움
RabbitMQ
→ 메시지 큐 기능에 더 특화됨
→ 복잡한 라우팅과 안정적인 메시징 요구사항에 적합작은 Django 프로젝트에서는 Redis로 시작하는 경우가 많습니다.
하지만 메시징 요구사항이 복잡하거나 큐 안정성이 매우 중요한 시스템에서는 RabbitMQ를 검토할 수 있습니다.
작업 결과는 꼭 저장해야 할까?
Celery task는 실행 결과를 저장할 수도 있고 저장하지 않을 수도 있습니다.
예를 들어 다음 작업은 결과를 꼭 저장하지 않아도 될 수 있습니다.
- 환영 이메일 발송
- 관리자 알림 전송
- 로그성 이벤트 처리
- 캐시 갱신
반면 다음 작업은 결과나 상태 조회가 필요할 수 있습니다.
- 보고서 생성
- 파일 변환
- 대용량 데이터 처리
- 사용자에게 진행률을 보여줘야 하는 작업
Result Backend를 사용하면 작업 상태를 조회할 수 있습니다.
result = generate_report.delay(user_id)
task_id = result.id나중에 작업 상태를 확인할 수 있습니다.
from celery.result import AsyncResult
result = AsyncResult(task_id)
print(result.status)다만 모든 작업 결과를 무조건 저장하면 저장소 부담이 커질 수 있습니다.
결과가 필요 없는 task는 결과 저장을 끄거나, 결과 만료 시간을 적절히 설정하는 것이 좋습니다.
재시도 처리하기
외부 API 호출이나 이메일 발송은 실패할 수 있습니다.
네트워크가 일시적으로 끊기거나, 외부 서비스가 잠시 장애일 수 있습니다.
이런 경우 Celery의 retry 기능을 사용할 수 있습니다.
from celery import shared_task
import requests
@shared_task(bind=True, max_retries=3)
def sync_external_data(self, user_id):
try:
response = requests.get(
f"https://api.example.com/users/{user_id}",
timeout=5,
)
response.raise_for_status()
except requests.RequestException as exc:
raise self.retry(exc=exc, countdown=60)이 코드는 외부 API 호출이 실패하면 최대 3번까지 60초 뒤에 재시도합니다.
재시도는 유용하지만 주의해야 합니다.
- 무한 재시도는 피해야 합니다.
- 재시도 간격을 적절히 둬야 합니다.
- 외부 서비스에 과도한 요청을 보내지 않아야 합니다.
- 같은 작업이 여러 번 실행되어도 문제가 없도록 설계해야 합니다.
idempotency가 중요한 이유
작업 큐에서는 같은 작업이 두 번 실행될 수 있다고 가정하는 것이 안전합니다.
네트워크 문제, worker 재시작, ack 처리 실패, 재시도 설정 등 여러 이유로 중복 실행 가능성이 생길 수 있습니다.
그래서 task는 가능하면 멱등성(idempotency)을 고려해야 합니다.
멱등성이란 같은 작업을 여러 번 실행해도 결과가 달라지지 않게 만드는 성질입니다.
예를 들어 이메일 발송 작업은 중복 실행되면 같은 이메일이 여러 번 갈 수 있습니다.
이를 방지하려면 발송 기록을 남기고 확인할 수 있습니다.
@shared_task
def send_invoice_email(invoice_id):
invoice = Invoice.objects.get(id=invoice_id)
if invoice.email_sent_at:
return "already sent"
# 이메일 발송
...
invoice.email_sent_at = timezone.now()
invoice.save(update_fields=["email_sent_at"])또는 외부 API 요청에 idempotency key를 사용할 수도 있습니다.
작업 큐에서는 “정확히 한 번만 실행된다”고 믿기보다, 중복 실행되어도 안전하게 설계하는 것이 중요합니다.
트랜잭션과 task 등록 순서
Django에서 DB 트랜잭션 안에서 task를 등록할 때 주의해야 합니다.
예를 들어 사용자를 생성하고 바로 task를 등록한다고 해보겠습니다.
user = serializer.save()
send_welcome_email.delay(user.id)대부분의 경우 문제없이 보일 수 있습니다.
하지만 트랜잭션이 아직 커밋되기 전에 worker가 task를 먼저 실행하면, worker가 DB에서 해당 사용자를 찾지 못할 수도 있습니다.
이럴 때는 transaction.on_commit()을 사용할 수 있습니다.
from django.db import transaction
user = serializer.save()
transaction.on_commit(
lambda: send_welcome_email.delay(user.id)
)이렇게 하면 DB 트랜잭션이 성공적으로 커밋된 뒤 task가 큐에 등록됩니다.
특히 모델 생성 직후 해당 객체 ID를 task에 넘기는 경우 on_commit을 고려하면 좋습니다.
task에는 어떤 값을 넘기는 것이 좋을까?
Celery task에 Django 모델 객체 자체를 넘기는 것은 피하는 것이 좋습니다.
나쁜 예시는 다음과 같습니다.
send_welcome_email.delay(user)대신 모델의 ID 같은 직렬화 가능한 값을 넘기는 것이 좋습니다.
send_welcome_email.delay(user.id)task 안에서 필요한 시점에 DB를 조회합니다.
@shared_task
def send_welcome_email(user_id):
user = User.objects.get(id=user_id)
...이 방식이 더 안전한 이유는 다음과 같습니다.
- task 메시지는 직렬화되어 broker에 저장됩니다.
- 모델 객체는 직렬화에 적합하지 않을 수 있습니다.
- task가 실행될 때의 최신 상태를 DB에서 확인할 수 있습니다.
- 메시지 크기를 줄일 수 있습니다.
task에는 가능하면 문자열, 숫자, 리스트, 딕셔너리처럼 직렬화하기 쉬운 값을 넘기는 것이 좋습니다.
주기적인 작업: Celery Beat
웹 서비스에서는 주기적으로 실행해야 하는 작업도 많습니다.
예를 들어 다음과 같습니다.
- 매일 새벽 통계 리포트 생성
- 10분마다 외부 API 동기화
- 매시간 만료된 세션 정리
- 매일 오래된 로그 삭제
- 매주 이메일 요약 발송
Celery에서는 Celery Beat를 사용해 주기적인 작업을 스케줄링할 수 있습니다.
예를 들어 Django 설정에서 주기 작업을 등록할 수 있습니다.
from celery.schedules import crontab
CELERY_BEAT_SCHEDULE = {
"sync-external-data-every-10-minutes": {
"task": "integrations.tasks.sync_external_data",
"schedule": 600.0,
},
"send-daily-report": {
"task": "reports.tasks.send_daily_report",
"schedule": crontab(hour=3, minute=0),
},
}Beat 프로세스는 별도로 실행해야 합니다.
celery -A myproject beat -l info운영 환경에서는 worker와 beat를 각각 별도 프로세스로 관리하는 경우가 많습니다.
작업 모니터링
백그라운드 작업은 사용자가 직접 보는 요청 흐름 밖에서 실행됩니다.
그래서 모니터링이 중요합니다.
확인해야 할 것은 다음과 같습니다.
- 큐에 작업이 얼마나 쌓였는지
- worker가 정상적으로 실행 중인지
- 작업 실패율이 높아지고 있지는 않은지
- 특정 작업이 너무 오래 걸리지는 않는지
- 재시도가 반복되고 있지는 않은지
- 브로커 연결이 불안정하지 않은지
Celery 작업 모니터링에는 Flower 같은 도구를 사용할 수 있습니다.
celery -A myproject flower또한 운영 환경에서는 로그와 메트릭을 함께 수집하는 것이 좋습니다.
예를 들어 다음 정보를 남기면 문제를 추적하기 쉬워집니다.
- task 이름
- task id
- 실행 시간
- 성공 여부
- 실패 원인
- 관련 user_id 또는 object_id
- 재시도 횟수
백그라운드 작업은 실패해도 사용자가 즉시 알아차리기 어렵기 때문에, 알림과 모니터링이 특히 중요합니다.
Celery를 Docker Compose로 실행하기
Docker Compose를 사용하면 Django, Redis, Celery worker를 함께 실행할 수 있습니다.
간단한 예시는 다음과 같습니다.
services:
web:
build: .
command: python manage.py runserver 0.0.0.0:8000
volumes:
- .:/app
ports:
- "8000:8000"
environment:
- CELERY_BROKER_URL=redis://redis:6379/0
depends_on:
- redis
worker:
build: .
command: celery -A myproject worker -l info
volumes:
- .:/app
environment:
- CELERY_BROKER_URL=redis://redis:6379/0
depends_on:
- redis
redis:
image: redis:7여기서 중요한 점은 web과 worker가 같은 코드를 사용하지만 서로 다른 프로세스로 실행된다는 것입니다.
web
→ HTTP 요청 처리
worker
→ Celery task 처리
redis
→ broker 역할운영 환경에서는 로그, 재시작 정책, 리소스 제한, healthcheck, secret 관리까지 함께 고려해야 합니다.
작업 큐를 도입할 때 주의할 점
작업 큐는 강력하지만, 무조건 도입한다고 문제가 사라지는 것은 아닙니다.
오히려 시스템 구성요소가 늘어나기 때문에 운영 복잡도도 증가합니다.
도입 전에 다음을 고려해야 합니다.
1. 작업 실패를 어떻게 처리할 것인가?
백그라운드 작업은 실패할 수 있습니다.
실패 시 재시도할 것인지, 관리자에게 알릴 것인지, 사용자가 다시 요청할 수 있게 할 것인지 정해야 합니다.
2. 중복 실행되어도 안전한가?
작업은 여러 번 실행될 수 있습니다.
이메일 중복 발송, 결제 중복 요청, 포인트 중복 지급 같은 문제가 생기지 않도록 설계해야 합니다.
3. 작업 순서가 중요한가?
일부 작업은 순서가 중요할 수 있습니다.
예를 들어 데이터 동기화 작업이 순서대로 처리되어야 한다면 큐 구성과 task 설계를 신중하게 해야 합니다.
4. 작업량이 갑자기 늘어나면 어떻게 할 것인가?
대량 이메일 발송이나 이미지 처리 작업이 갑자기 몰릴 수 있습니다.
worker 수를 늘릴 수 있는지, 큐를 분리할지, rate limit을 둘지 고민해야 합니다.
5. 사용자에게 진행 상태를 보여줘야 하는가?
보고서 생성처럼 오래 걸리는 작업은 사용자가 진행 상태를 보고 싶어 할 수 있습니다.
이 경우 task id를 저장하고 상태 조회 API를 만들어야 할 수 있습니다.
Celery를 사용할 때 자주 하는 실수
1. task를 일반 함수처럼 호출하는 경우
send_welcome_email(user.email)이렇게 호출하면 백그라운드 작업이 아니라 현재 요청 안에서 실행됩니다.
작업 큐에 등록하려면 다음처럼 호출해야 합니다.
send_welcome_email.delay(user.email)2. worker를 실행하지 않는 경우
task를 큐에 등록해도 worker가 없으면 작업은 처리되지 않습니다.
개발 환경에서도 Redis와 worker가 실행 중인지 확인해야 합니다.
3. task에 모델 객체를 직접 넘기는 경우
모델 객체 대신 ID를 넘기고, task 안에서 다시 조회하는 편이 안전합니다.
send_welcome_email.delay(user.id)4. 트랜잭션 커밋 전에 task를 등록하는 경우
DB에 아직 커밋되지 않은 객체를 task가 먼저 조회하려고 하면 문제가 생길 수 있습니다.
이 경우 transaction.on_commit()을 고려합니다.
5. 재시도 정책 없이 외부 API를 호출하는 경우
외부 API는 실패할 수 있습니다.
타임아웃, 재시도 횟수, 재시도 간격을 명확히 두는 것이 좋습니다.
6. 모든 작업을 하나의 큐에 넣는 경우
이메일 발송, 이미지 처리, 데이터 동기화 작업을 모두 하나의 큐에 넣으면 무거운 작업 때문에 가벼운 작업이 밀릴 수 있습니다.
작업 성격에 따라 큐를 나누는 것도 고려할 수 있습니다.
email queue
image queue
sync queue7. 모니터링 없이 운영하는 경우
백그라운드 작업은 실패가 눈에 잘 띄지 않을 수 있습니다.
worker 상태, 큐 길이, 실패율, 재시도 횟수, 실행 시간을 모니터링해야 합니다.
Celery를 공부할 때 추천하는 순서
Celery를 처음 공부한다면 다음 순서로 접근하면 좋습니다.
- 작업 큐가 필요한 이유를 이해합니다.
- Producer, Broker, Worker 개념을 익힙니다.
- Redis를 broker로 사용해 Celery를 실행해봅니다.
- 간단한 task를 만들고
delay()로 호출해봅니다. - Django view에서 task를 등록해봅니다.
- worker 로그에서 작업 실행을 확인합니다.
- 실패와 retry를 처리해봅니다.
transaction.on_commit()이 필요한 상황을 이해합니다.- task에 모델 ID를 넘기는 패턴을 익힙니다.
- Celery Beat로 주기 작업을 실행해봅니다.
- 큐 분리와 모니터링을 검토합니다.
처음부터 복잡한 분산 작업 구조를 만들 필요는 없습니다.
이메일 발송 같은 작은 작업부터 분리해보면 Celery의 흐름을 이해하기 쉽습니다.
정리
Celery는 Python에서 백그라운드 작업을 처리할 때 많이 사용하는 작업 큐 도구입니다.
Django 프로젝트에서는 오래 걸리거나 실패 가능성이 있는 작업을 웹 요청 밖으로 분리하는 데 유용합니다.
핵심을 정리하면 다음과 같습니다.
- 오래 걸리는 작업을 웹 요청 안에서 처리하면 응답 시간이 길어질 수 있습니다.
- 작업 큐는 나중에 처리해도 되는 작업을 큐에 넣고 worker가 처리하는 구조입니다.
- Celery는 Python에서 많이 사용되는 분산 작업 큐 라이브러리입니다.
- Celery는 보통 Redis나 RabbitMQ 같은 broker와 함께 사용합니다.
- Django 웹 서버는 task를 큐에 등록하고, Celery worker가 실제 작업을 처리합니다.
delay()나apply_async()를 사용해 task를 큐에 넣을 수 있습니다.- task에는 모델 객체보다 ID 같은 직렬화 가능한 값을 넘기는 것이 좋습니다.
- DB 트랜잭션 커밋 이후 task를 등록해야 할 때는
transaction.on_commit()을 고려합니다. - 외부 API 호출이나 이메일 발송처럼 실패 가능한 작업에는 retry 전략이 필요합니다.
- task는 중복 실행되어도 안전하도록 멱등성을 고려하는 것이 좋습니다.
- 주기 작업은 Celery Beat로 실행할 수 있습니다.
- 운영 환경에서는 worker 상태, 큐 길이, 실패율, 실행 시간을 모니터링해야 합니다.
Celery를 잘 활용하면 사용자 요청은 빠르게 응답하고, 오래 걸리는 작업은 안정적으로 백그라운드에서 처리할 수 있습니다.
다만 작업 큐를 도입하면 Redis나 RabbitMQ, worker, 모니터링까지 관리해야 하므로 운영 복잡도도 함께 늘어납니다.
따라서 작은 작업부터 분리하면서 점진적으로 구조를 잡는 것이 좋습니다.
참고 링크
'백엔드 실무' 카테고리의 다른 글
| 웹훅(Webhook) 이해하기: 외부 서비스 이벤트를 서버에서 받는 방법 (0) | 2026.05.13 |
|---|---|
| GitHub Actions로 CI/CD 이해하기: 테스트부터 Docker 이미지 빌드까지 (0) | 2026.05.12 |
| Django REST Framework 이해하기: Serializer, ViewSet, Router 기본 흐름 (0) | 2026.05.12 |
| Django 템플릿에서 DB 쿼리를 조심해야 하는 이유 (0) | 2026.05.11 |
| Django 쿼리 최적화 이해하기: N+1 문제와 select_related, prefetch_related (0) | 2026.05.11 |